Laymen’s Guide to Alerts with Kubernetes and Alertmanager
Prometheus is well known to enable great-looking Grafana Dashboards. But there is another important companion: Alertmanager. This article covers the basics and invites you to explore Alertmanager by using K3D and kube-prometheus-stack.
The article wants to enable you to experiment and try things yourself — be hands-on. We are going to set up a complete K3D cluster with a few components, including a custom NodeJS application, ingress-nginx, and kube-prometheus-stack. We demonstrate how to create and manage alerts using Alertmanager. The K3D setup is based on a previous article covering the use of Lens with K3D, which is included in this setup as well.
Update February 13, 2022: There is a newer version of the software here with several updates.
What you need to bring
The setup is based on Docker 20.10, NodeJS 14.17, Helm3, and K3D 5.0.1 (note that K3D version 5 introduced some changes in the configuration syntax). Before getting started, you need to have the components mentioned above installed by following the standard installation procedures. The article is based on Ubuntu 21.04 as OS, but other OSs will likely work as well. A basic understanding of bash, Docker, Kubernetes, Grafana, and NodeJS is expected. You will need a Slack account.
All source code is available at Github via https://github.com/klaushofrichter/alertmanager. The source code includes a few bash scripts and NodeJS code. As always, you should inspect code like this before you execute it on your machine, to make sure that no bad things happen.
Environment Setup
Before doing experimentation, you will need to create the K3D cluster and install a few components. It’s straightforward: clone/download the repository, edit some configuration, and run ./start.sh.
Here is a slightly simplified section of the configuration file config.sh:
export HTTPPORT=8080
export CLUSTER=mycluster
export GRAFANA_PASS="operator"
export SLACKWEBHOOK=$(cat ../.slack/SLACKWEBHOOK.url)
export AMTOOL=~/bin/amtoolHTTPPORTis the localhost port that is used to access all services, including the NodeJS server API, Grafana, Prometheus, and Alertmanager.ingress-nginxhelps with the routing.CLUSTERis the name of the K3D cluster.GRAFANA_PASSis the password of the admin account in Grafana.SLACKWEBHOOKis the full URL to post Slack messages to. It’s a URL, similar to this:https://hooks.slack.com/services/ABCDEFG....— in the config file we expect the URL to be in a different directory that is not accidentally going to be shared, but you can put the URL directly intoconfig.shas well. See more detail about this in the next chapter.AMTOOLis the full path toamtool, a binary that comes with Alertmanager, but not with the helm installation that we use. You will need to download and install it separately if you want to do that.amtoolis optional for this article. You can download Alertmanager from here (e.g. alertmanager-0.23.0.linux-amd64.tar.gz), and extract theamtoolbinary from the tar.gz file. Adjust theAMTOOLvariable to point to the binary location.~/binseems like an obvious choice.
There are a few more things happening in the config.sh file, e.g. extracting the application name and version from package.json, but these may not need to be customized.
Preparing Slack
We will need a Slack webhook to post alerts to Slack. Alertmanager supports a lot of ways to get your attention, but Slack seems to be the most simple and accessible path. So this article covers only Slack, which is very straightforward.
Visit Slack at https://slack.com and create an account or login with your existing account. You can create a new channel (e.g. “alerts”) and then follow instructions to generate a webhook that can be used to post messages to that new channel.
You will see a URL and you should take note of it. Since this includes some level of authorization, you should keep this URL a secret. But it needs to be stored somewhere… one solution is to arrange for a file with proper access protections and avoid sharing that file.
At the end of the day, the URL needs to end up in the environment variable SLACKWEBHOOK. config.sh expects the URL in the file ../.slack/SLACKWEBHOOK.url, but you can certainly use other methods.
TL;DR
After customizing config.sh and getting the SLACKWEBHOOK, we are all set to get started by calling ./start.sh and wait for a few minutes. If things go well, you should receive a slack message about starting the installation, one about setting up Alertmanager, and one about finishing the installation. The terminal window should then show a few URLs that can be visited:
http://localhost:8080leads to the Grafana UI. You can login withadminand the password that is shown inconfig.sh(operator, unless you changed it), visitmanageand pick a dashboard to look at.http://localhost:8080/promis for the Prometheus UX — it’s less exciting compared to Grafana, but we check this out later for more details about alerting rules. For now, the status of the targets shown athttp://localhost:8080/prom/targetsis most interesting, they should all turn “blue” after a few minutes, meaning that the components that are to be monitored by Prometheus are successfully scraped.http://localhost:8080/alertis the Alertmanager UX. You should see three alerts after a few minutes — one Watchdog, and two tests.http://localhost:8080/service/metricsshows the metrics coming from the NodeJS app. You can generate some records by going to the actual API for a random number here or some server info there. There is some discussion about these metrics here.
The installation already includes a large number of alerting rules. You can see them all at http://localhost:8080/prom/alerts. Note that you can filter the alerts to see only those that are currently inactive (i.e. the condition behind the rule is not met), pending (i.e. the condition is met, but there is a certain time configured before the rule is actually firing), and firing. Firing rules should be processed by Alertmanager and possibly routed to receivers such as Slack — more about that later.
Let’s fire an Alert
With the system running, it is now time to trigger an alert… there is a rule in place that fires when the number of replicas of the NodeJS app is larger than 2. Let’s scale-up!
./scale.sh 6This will scale up, and more instances of the NodeJS app will created. You can check it out:
export KUBECONFIG=~/k3d/kubeconfig-mycluster.yaml
kubectl get pods -n amlearnAfter a little while, you should receive a Slack notice. The timing here is a matter of configuration. If you can’t wait, check out localhost:8080/prom/alerts to see the alert pending and eventually firing. There may be a few amlearnPods alerts.
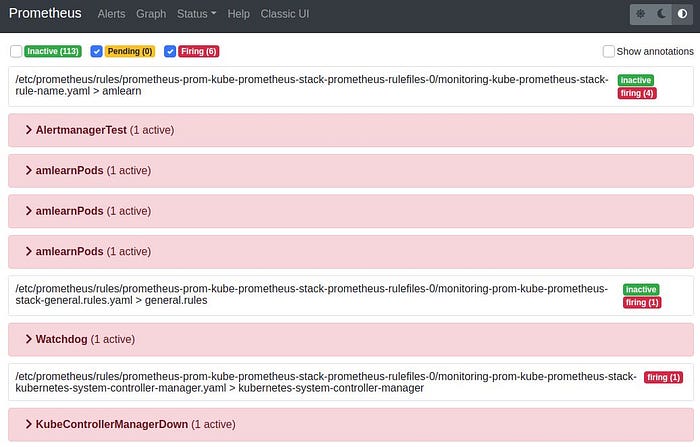
Eventually, something should show in Slack:

Without going into details about what is shown there, let’s first fix the problem:
./scale.sh 2This will scale down the deployment back to two instances. Eventually, the alert condition that fired the alert shown in Slack is not met anymore. As a result, a RESOLVED message is posted. The crisis is averted, the cluster is healthy again!
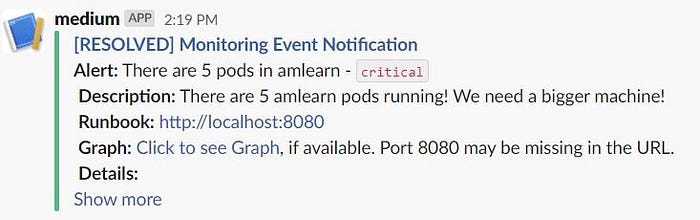
The RESOLVED message in this particular case is actually a bit odd: it repeats the original message that triggered the alert (which is expected), but the text now talks about five pods, not six, as we have seen in the original alert.
Here is the probable background: There is a configuration that triggers the same amlearnPods alert for various numbers of pods, but with different severity. There is also a configuration that only posts the highest priority alert to Slack if there are several conditions firing for the same alert, which is why we have multiple instances of the same alert in the Alertmanager UX. The RESOLVE message is sent only once, and it appears that the timing of the measurement triggered a lower priority message content, instead of the one that was submitted by Alertmanager. That may be a bug, but it does not matter too much, as the point of the message is that the alert named amlearnPods is resolved, regardless of the text of the RESOLVED message.
What are all these YAML files good for?
Before going a bit deeper and seeing where these alerts come from, let’s look at the files that we have in the repository: There are a few YAML files, and below is explained is what they are good for. Actually, there are *.yaml.template files, not *.yaml: The .template means that there are environment variable substitutions using envsubst performed to generate the actual *.yaml — but this is done by the scripts that come with the setup, and you may not need to worry.
extra-am-values.yaml.templateis a pretty busy alertmanager configuration file — this is a values file forkube-prometheus-stack, and this is the core of this article. Therefore, we have an extra section about his file later. This file is the only file other thanconfig.shthat you should need to customize for further experimentation.am-values.yaml.templateis a less busy alertmanager configuration file. This only contains the basics, and it is not used by any script. It can be useful to start with a minimum configuration. If you want to use it when starting the cluster, please check outconfig.shand select the appropriate value forAMVALUES. The result will be that there are none of the demonstration rules applied.prom-values.yaml.templateis akube-prometheus-stackvalues file with everything other than the configuration of alertmanager. Among other things, it includes some settings for ingresses so that Grafana, Prometheus, and Alertmanager can be accessed locally viahttp://localhost:port. You can add additional configurations for Grafana and Prometheus here.app.yaml.templatedescribes how the NodeJS application is to be deployed. It includes pods, deployments, services, and ingresses.amtool-config.yaml.templateis a very simple configuration file foramtool. The YAML will need to go to~/.config/amtool/config.yml, which is one of two places where this config can go. It is copied automatically by the scripts, ifamtoolitself is installed.dashboard.json.templateis a custom Grafana Dashboard. Details about that are in another article.k3d-config.yaml.templateis the config file for the k3d cluster itself.
What are all these Bash Scripts good for?
Here are the scripts that come with the repository:
start.shis doing it all: remove an existing cluster to have a clean start, create a new cluster, installingress-nginx, installkube-prometheus-stack, build a container fromserver.jsand deploy it. The script is deliberately waiting a lot for things to get installed, and services to be exposed, so this will take a few minutes…prom.shis used bystart.shto deploykueb-prometheus-stack. This can be called separately (afterstart.shcreated the cluster itself). There is a companion scriptunprom.shthat deletes the Prometheus release. This can be used to have a fresh start with Prometheus without removing the whole cluster.upgrade.shcan be called when thekube-prometheus-stackhelm chartextra-am-values.yamlwas changed, without reinstalling Prometheus and other components.scale.shtakes a number as a parameter, and will scale the NodeJS application running in the cluster accordingly../scale.sh 4will result in four replicas running. This is used to trigger alerts.test.shis running a very simple test of the alertmanager by calling its API directly withcurl.slack.shtakes one argument ( e.g../slack.sh "Hello World!") and sends that argument to the configured Slack channel. It’s a good way to test the Slack web hook, and the./slack.hscript is used to pass occasional messages to Slack, like “installation completed”.
The scripts are supposed to help you doing experimentation: change something in the configuration files, and then either restart the whole cluster with ./start.sh, or reinstall kube-prometheus-stack with ./prom.sh, or upgrade the helm release for kube-prometheus-stack through ./upgrade.sh. Obviously, restarting the cluster takes the most time, but it pretty much makes sure that there is no residual setting. The ./upgrade.sh path is the fastest, but at times it may not be enough to propagate all changes.
Explore Prometheus UI
Now let’s look at the Prometheus targets via the UI as shown:

The first two list entries are the custom targets for the NodeJS server.js application. There is one for the Pods (we scaled up to six again, therefore we see the number 6) and one for the service. The configuration for that is in prom-values.yaml.template, look for additionalScrapeConfigs:. The other list entries are metric targets that come with kube-prometheus-stack.
Now let’s look at the rules:
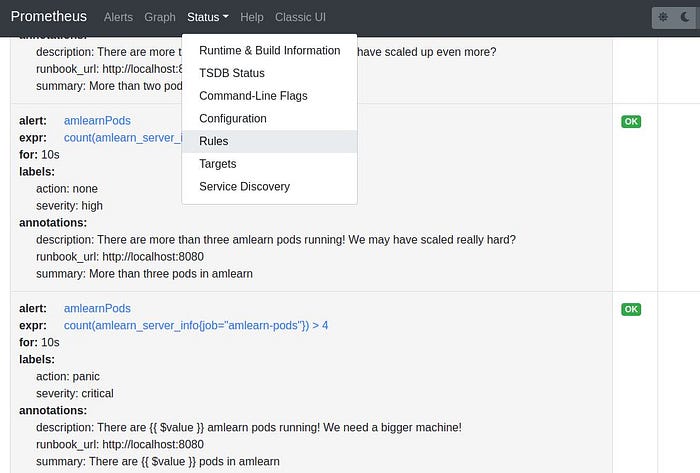
kube-prometheus-kube comes with quite a few pre-configured rules. Some may not work in a specific environment, such as a rule firing an alert due to the absence of KubeControllerManager, or the lack of etcd. It is possible to disable such rules (see the top of extra-am-values.yaml.template, but the specific KubeControllerManager rule can’t be disabled through the values file (bug?). As there is no KubeControllerManger component in K3D, the rule fires (you can see it in the screenshot earlier about the six pods), but some other configuration silences the alert so that there is no Slack message coming to you.
The screenshot above shows the rule that responded to the six pods after scaling up. It is defined in extra-am-values.yaml.template, let's have a closer look:
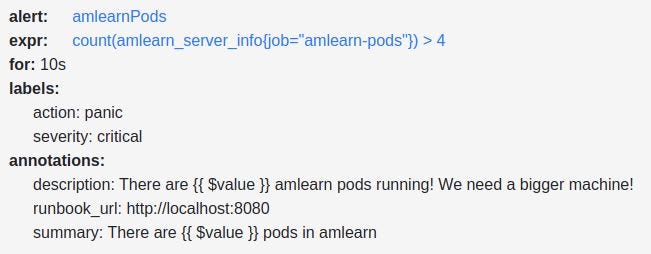
alert: <string>defines the name of the alert. Note that you can have the same alert name used multiple times.expr: <some PromQL expression>defines the condition that activates the rule. In this case, we count the number of responses to the custom metric that we have available from the pods and compare it with a threshold. You can click on the expression, and go to a live evaluation page for that rule, which also includes a graph, see below. Now you can change the query and experiment yourself. This is specifically useful to figure out things like memory usage or CPU consumption.
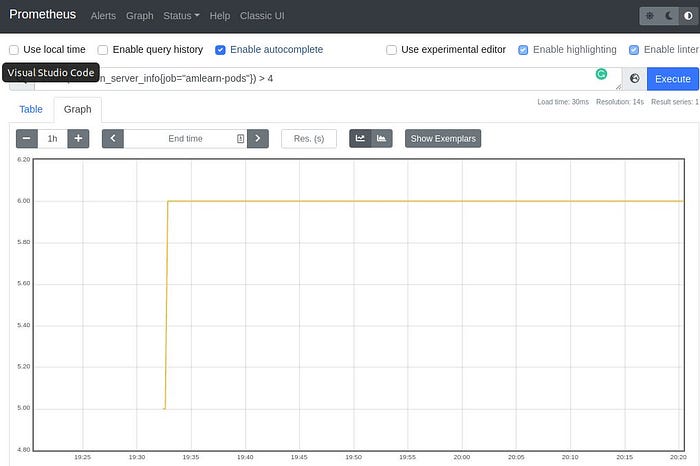
for: <time>indicates how long the expression needs to be true to fire the alert. In this case, if we have 10 seconds of this condition, it will fire. Now, there is a caveat here: the expression evaluation is usually not done every 10 seconds, but probably 30 seconds or even less frequently— this can be configured per scrape. So10sis not much different from30sor any other number smaller than the evaluation interval.labels: <string>is a list of Key-Value Pairs that can be used later for filtering. One of the options is to use the keyseverity. But please note that theseverityvalue is not defined by Prometheus, and you will need to make sense of the values yourself. There may be some common sense values for a key likeseverity, in this case, saylow,medium,highandcritical, but this is more a convention than a rule. Some of the pre-defined rules use specific values, which you should be aware of so that they would be handled when needed.
You can have your own labels, in the example we haveaction: panicwhich is more humorous than serious… it would make sense to use such data for further automation, e.g. determine whom to alert.annotations: <string>is somewhat more for human-readable text. It is possible to insert certain dynamic values such as the result of the expression{{ $value }}.
Much of the content of this alert definition is ending up in the Slack message. For comparison, here is the Slack message from before again, with Slack’s Show more enabled:

We discuss the Slack message formatting later.
Explore Alertmanager UI
The Alertmanager comes with its own UI. We’ll start with the silences via http://localhost:8080/alert/#/silences:

A silence is a configuration to prevent an alert from being propagated to receivers or shown in the alerts UI page. After the installation, there is only one silenced alert, the KubeControllerManagerDown alert, which does not make sense for K3D. But it fires anyway, so here we prevent it from showing in Slack. The Silence is configured in this case through a direct call to Alertmanager via curl. Have a look at test.sh:
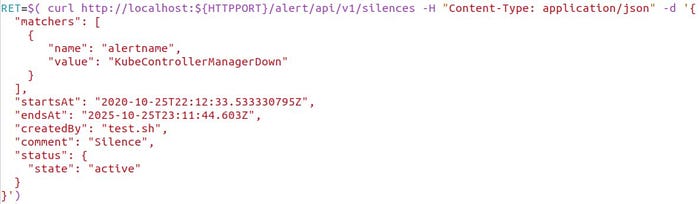
This is one way to configure silences, although this is possibly not officially supported. The key point is that there is a matching condition for the label alertname, and in this case the silence applies to alerts about kubeControllerManagerDown.
The other interesting page in the Alertmanager UI is the alerts page. It shows alerts that are firing, independent of propagation to other receivers such as Slack. This UI can be the principal console for alerts, as everything flows through it.

The alerts are grouped here by the label severity. This setting is done in extra-am-values.yaml.template, look for group-by: in the route section.
We can see the dreaded amlearnPods alert in the list, with the labels exposed. You can see the annotations by clicking on + info. The source link may not work, as it is lacking the port — perhaps there is a config for that somewhere :-)
The Alertmanager UI is quite useful to see what is going on and to analyze the routing. But the real task of Alertmanager is the execution of the routes, defined in the YAML files discussed below.
Before going there: as we have created silences with a curl call, we can also create alerts, see test.sh again:
This type of API makes it very easy to integrate alerts that are not coming from Prometheus into the same pipeline. Again, this may not be officially supported, but it makes sense to have.
Review extra-am-values.yaml
After all that, the basics of Prometheus and Alertmanager may be more clear by now— but there is a lot more detail. We can only scratch the surface here, but a walk through the values file for Alertmanager extra-am-values.yaml.template exposes some useful stuff:
defaultRules:
defaultRules:
create: true
rules:
etcd: false
kubeScheduler: falseThis part instructs Prometheus to install all the rules that are pre-defined. In this case, however, etcd and kubeScheduler don’t make sense with k3d, so these get the false. Unfortunately, there is no option to disable kubeControllerManager, and that’s why we did the extra work of silencing alerts related to KubeControllerManager. BTW, the rules are config files and can be found in the Prometheus pod like this:
kubectl exec prometheus-prom-kube-prometheus-stack-prometheus-0 -n monitoring -- ls /etc/prometheus/rules/prometheus-prom-kube-prometheus-stack-prometheus-rulefiles-0additionalPrometheusRulesMap:
That part contains additional rules that are defined. The section shown below covers only one of many:
additionalPrometheusRulesMap:
rule-name:
groups:
- name: ${APP}
rules:
- alert: ${APP}UP
expr: absent(up{job="${APP}-services"})
for: 1m
labels:
severity: critical
action: panic
annotations:
summary: "No ${APP} Service Provision"
description: "The ${APP}-service does not provide
an UP signal."
runbook_url: http://localhost:${HTTPPORT}/service/infoNote that ${APP} and ${HTTPPORT} values are is substituted by envsubst before the rule is loaded into Prometheus. Other noteworthy things:
runbook_urlis just a dummy URL here. In real life, this should be a link to a place with instructions about how to deal with this type of alert.expr: absent(up{job="${APP}-services"} == 1)is the firing condition. This uses theupmetric from the service associated with the NodeJS application. We can test this by removing replicas:./scale.sh 0.
When this becomes noticed by Prometheus for more than one minute, we can see a Slack message coming in. The slack message repeats after a little while (see details about that below), and after./scale.sh 2and some time, aRESOLVEDmessage will show in Slack.
Also noteworthy: there is another alert defined that responds to theupmetric, calledTargetDown. This comes withkube-prometheus-stackand will fire after 15 minutes on anyupmetric, so it is worth waiting that long. You can then see the definition in the Prometheus alert list. Once the alert is resolved after the./scale.sh 2command, you are going to get twoRESOLVEmessages.action: "panic"is just a label that could be used to trigger extra activity — this is not a value processed or defined by Prometheus or Alertmanager.
alertmanager:
In our specific case. there are a lot of configurations for alertmanager in extra-am-values.yaml. We ignore them all until we come to config:
config:
#global:
# slack_api_url: ${SLACKWEBHOOK}slack_api_urlis the place where the Slack webhook URL is placed. In this case, we are usingenvsubstto insert the value from an environment variable before applying the values YAML, instead of coding it directly.
However, this is commented out here, in favor of a URL configuration for an individual receiver — by that way, several different Slack channels can be utilized, e.g. for different audiences or specific alert labels.
config:
...
route:
receiver: "slack"
group_by: ["severity"]
group_wait: 30s
group_interval: 2m
repeat_interval: 12hThe route: section is pretty lengthy, the part shown above covers settings that apply to all routes defined later.
receiver: "slack"tells us that all routes should use the receiver with the nameslack, unless it’s overwritten for a specific route.group_by: [ <list of label names> ]informs Alertmanager that alerts should be grouped by certain labels when sending alerts and showing alerts in the UI. In this case, we group byseverityonly.group_wait: <duration>causes Alertmanager to wait for a time to collect alerts within the same group.group_interval: <duration>instructs Alertmanager to avoid sending alerts for the same group until the<duration>passed.repeat_interval: <duration>lets Alertmanager send the same alert again if it is still valid.
The routes section shown below determines how to actually handle alerts by assigning specific receivers to match label conditions.
config:
...
route:
...
routes:
- match:
severity: "none"
receiver: "null"
- match:
alertname: "KubeControllerManagerDown"
receiver: "null"
- match:
alertname: "${APP}Down"
repeat_interval: 2m
- match:
severity: "critical"
repeat_interval: 10m- The section
match: severity: "none"assigns all alerts that have the labelseveritywith the valuenoneto thenullreceiver. This receiver is defined later, and it’s basically/dev/null. Alerts withserverity: nonewill show up in the Alertmanager UI, but they would not be sent to Slack. - The section about
KubeControllerManagerDownalso prevents an alert to go out to the"slack"receiver. The alert does show up in the Alertmanager UI… however, it is also silenced per the./test.shscript. In that sense, this route here is not needed, as silenced alerts would not be sent to receivers anyway. - The alert
amlearnDownwhich we triggered by./scale.sh 0goes to the"slack"receiver by default, but it repeats every two minutes per therepeat_interval: 2moverwrite. - All other alerts that are
criticalrepeat every 10 minutes, per the final definition.
If a severity: medium alert would happen, it would be sent to the slack receiver, but repeat only after 12 hours.
config:
...
inhibit_rules:
- source_match:
severity: "medium"
target_match:
severity: "low"
equal:
- alertname
- source_match:
severity: "high"
target_match_re:
severity: "(low|medium)"
equal:
- alertname
- source_match:
severity: "critical"
target_match_re:
severity: "(low|medium|high)"
equal:
- alertnameThe inhibit_rules section provides meaning to the values of the severity label. Let's look at the first part:
- source_match:
severity: "medium"
target_match:
severity: "low"
equal:
- alertnameThis means: if there are several alerts firing with the same value for the label alertname, send only the alert with the label severity: medium and ignore those with the label severity: low. That definition puts preference on medium vs low.
The next two sections put the “ranking” of high above low and medium, and the ranking of critical above high, medium and low. Note that the matching here is using match_re which allows using regular expressions.
You can test this again: ./scale 4 creates four replicas of the NodeJS service, and there are amlearnPods alerts defined: a low severity for 3 pods, high for 4 and critical for five or more. After a little while, you should get a high severity alert, which repeats after 12 hours. The low and medium alerts are inhibited, and the critical alert is not firing. The default repeat_interval of 12 hours applies. './scale.sh 2 settles everything.
The final section defines the receivers… there is a fragment of this part shown below:
receivers:
- name: "null"
- name: "slack"
slack_configs:
- api_url: ${SLACKWEBHOOK}
send_resolved: true
title: '[{{ .Status | toUpper }}....'
text: >-
{{ range .Alerts }}
...name: "null"defines thenullreceiver which was used before. There is no further definition there, so no action is taken and alerts routed tonullare not going anywhere.name: "slack"defines the details of the Slack receiver.api_urlcarries the Slack webhook that we created earlier. The value is inserted here viaenvsubstbefore the YAML is applied. This placement of the webhook as opposed to the global value enables you to create multiple receivers for different Slack channels. Note that a Slack webhook is only good for one specific channel, and therefore it is not needed to specify the target Slack channel here.send_resolved: truewill causeRESOLVEDmessages for alerts that are not firing anymore.title:andtext:informs how the Slack message is to be formatted. This includes some inclusion of context data as shown.
amtool: a useful tool, somewhat hidden
The test.sh script in the repository uses amtool, if available. This tool is quite useful but optional. The tool allows communication with Alertmanager, and can generate some insight. If you installed amtool, you should have seen some output as part of ./test.sh:

Call amtool help for information about other options. Please note also that there is a Prometheus companion tool as well, called promtool, as part of the Prometheus binary distribution.
Where to go from here
Despite its length, this article does not go into a lot of detail, but it does cover everything to get started with a fully functional system setup. The intent is that you would be equipped with a simple and safe environment to do your own stuff and research deeper when there is a need or interest.
The starting point for more details is of course the Alertmanager original documentation. A lot of alert rules can be found here. And here is a collection of “Gotchas”. And there is more… thanks to everyone who shares useful information.
This article does not cover best practices or advise how a good alert should look like. The Alertmanager documentation refers to this article from Rob Ewaschuk, and there are certainly many other articles and books with good insight.
The setup used for this article is also not complete by any means, for example, there is no persistent storage, and changes you may do, for example in Grafana’s dashboard editor, will not survive a call to ./start.sh or ./prom.sh.
So please take it as it is if it’s useful to you, and explore further. Happy Coding!
